GPU as resources
AI-related resources such as acceleration devices need to be identified to provision AI microservice with Fog Platform. There are various types of acceleration devices, even an ARM-based SoC is now can be used for edge resources. DECENTER platform supports those GPU nodes, either on cloud or edge, to make it able to deliver the intelligence with respect to the architecture and devices it’s going to run.

QoS-aware orchestration
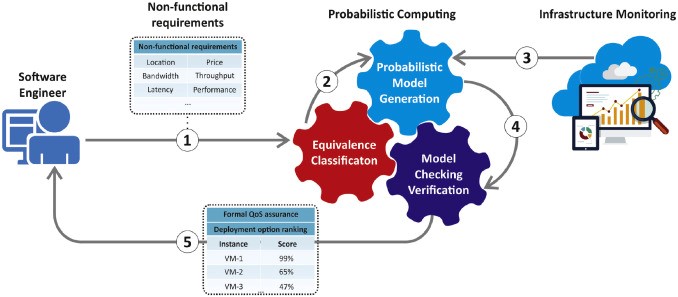
One of DECENTER’s key innovations is focused on the deployment phase, particularly when the software engineer has to select an appropriate IaaS offer to (re)deploy a containerized AI method in the edge-to-cloud continuum. The Quality of Service (QoS) and Non-Functional requirements (NFRs) of AI methods vary greatly, which must be addressed in the deployment phase. For example, for a specific AI method, it may be necessary to obtain a high-speed CPU processor, a large amount of memory, low latency, high bandwidth, a specific geolocation for deployment, achieve low operational cost or similar, whilst another method may require high-speed GPU processor. Therefore, the problem of selecting an appropriate computational resource, that is, an infrastructure and configuration scheme where a microservice will be deployed and run is not at all unimportant. The more criteria used, the higher the complexity of the decision-making process.
Therefore, within the DECENTER project a new method is being researched and developed that can be used by software engineers to automatically rank a list of cloud deployment options for their microservices. The goal of this innovation contends that formal QoS assurances in the application deployment phase can be provided with a new probabilistic decision-making method. Our approach relies on the theory and practice of stochastic Markov models. Hence, the objectives of this work have been set out to develop:
- a Markov-based probabilistic decision-making approach, which offers the software engineer a set of optimal IaaS that would satisfy a specific QoS of the application;
- an equivalence classification approach of available cloud deployment options to reduce the computational time of the decision-making process,
- a design and implementation of the new method within in DECENTER to facilitate (re)deployment operations.
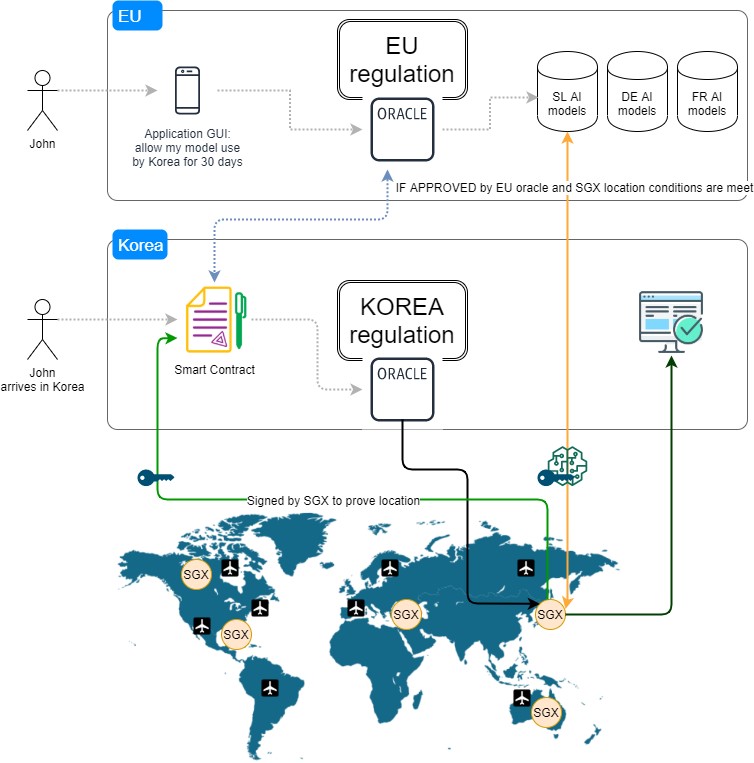
Cross-border data-management
In the Big Data era, the variety, velocity, volume and other aspects of data are prominent and are currently being addressed by many researchers world-wide. Within the DECENTER project, we focus on the cross-border data-management of the DECENTER use cases. In this context, a basic Big Data pipeline starts from a camera that provides a raw video stream. The AI processing models/methods are distributed to various resources, which means that we need to deal with different input and output data streams. In the final stage, an outcome of the AI process takes the format of a structured file with specific information derived from the video-stream, for example, the identity of the person shown on the video.
The key innovation is specific cross-border data management mechanisms that enable the participating entities control all aspects of the data transport and management when it comes to their administrative domains. Apparently, the requirements extracted by specific parties taking part in a data management scenario may be too hard in which case it may prove impossible to establish the required quality of cross-border data management and transport. For instance, a futuristic European regulation may require certification for dealing with sensitive private data of all cloud providers that process personalised AI models/methods, another futuristic Korean regulation may require to process sensitive data of Korean citizens only on hardware resources that are capable of using strong security mechanisms (e.g. SGX chips). Furthermore, new GDPR-like European legislation may require to empower the citizen with an ability to approve or disapprove the use of her/his own personalised AI model in specific settings, such as at an airport in Korea. In such case, the cross-border data management mechanisms must be designed in a way to allow strict assessment and application of the user’s preferences in the specific context where the use of AI will be required.